출처 : https://techcrunch.com/2019/01/24/starcraft-ii-playing-ai-alphastar-takes-out-pros-undefeated/

스타 크래프트에서 컴퓨터를 잃는 것은 1998 년 첫 게임이 나온 이래로 내 전통이었습니다. 물론 내장 된 "인공 지능"은 심각한 플레이어가 이기기는 쉽지 않았으며 수년 동안 연구자들은 인간의 전략을 복제하려고 시도해 왔습니다. 최신 버전의 게임 기술 AlphaStar는 최근에 두 명의 주요 프로를 5-0으로 이겼습니다.
새로운 시스템은 DeepMind 에 의해 만들어졌으며 여러면에서 "전통적인"StarCraft AI라고 할 수있는 것과는 아주 다릅니다. 당신이 게임에서 선택할 수있는 컴퓨터 상대는 정말로 꽤 바보입니다. 그들은 기본 내장 전략을 가지고 있으며 공격과 방어 방법과 기술 트리를 어떻게 진행할 것인지 일반적으로 알고 있습니다. 그러나 그들은 인간성을 강하게하는 모든 것을 갖추고 있습니다 : 적응력, 즉흥과 상상력.
AlphaStar는 다릅니다. 그것은 인간이 처음에는 놀는 것을 보면서 배웠지 만, 곧 그 자신의면에 대항하여 기술을 연마했습니다.
첫 번째 반복은 "마이크로"(즉, 효과적으로 유닛을 제어하는 것)와 "매크로"(게임 경제와 장기 목표) 전략의 기초를 배우기 위해 게임의 재연을 지켜 보았습니다. 이 지식을 바탕으로 게임 내 컴퓨터 상대방을 95 %의 가장 힘든 상황에서 이길 수있었습니다. 그러나 어떤 프로라도 당신에게 말할 것입니다, 그것은 아이의 놀이입니다. 그래서 실제 작업이 여기서 시작되었습니다.

수 백명의 대리인이 산란되었고 서로 마주 쳤다.
스타 크래프트는 매우 복잡한 게임이기 때문에 모든 상황에서 사용할 수있는 최적의 단일 전략이 있다고 생각하는 것은 어리석은 일입니다. 그래서 기계 학습 에이전트는 본질적으로 수백 가지 버전의 버전으로 나뉘 었습니다. 각각은 약간 다른 작업이나 전략이 주어졌습니다. 누구나 공중 우월을 달성하려고 시도 할 수도있다. 다른 하나는 티칭에 집중할 것입니다. 노동자 러시와 같은 다양한 "치즈"시도를 시도하는 또 다른 사람. 일부는 강력한 에이전트를 대상으로 삼아 다른 전략은 신경 쓰지 않고 이미 성공한 전략을 이기고있었습니다.
이 에이전트의 계열은 수백 년 동안의 게임 시간 (물론 평행하게 수행 됨) 동안 싸우고 싸웠습니다. 시간이 지남에 따라 다양한 요원들은 지역 효과 공격 (Area-of-effect attack)하에있는 유닛을 흩어지게하는 법과 복잡한 여러 갈래의 범죄에 이르기까지 다양한 사안을 배웠습니다. 이들 모두를 합치면 약 200 년의 게임 플레이를 통해 매우 견고한 AlphaStar 에이전트가 탄생했습니다.
대부분의 스타 크래프트 II 전문가는 200 세보다 훨씬 젊기 때문에 약간의 불공정 한 이점이 있습니다. AlphaStar는 어쨌든 최초의 화신으로 다른 두 가지 주요 이점을 가지고 있습니다.
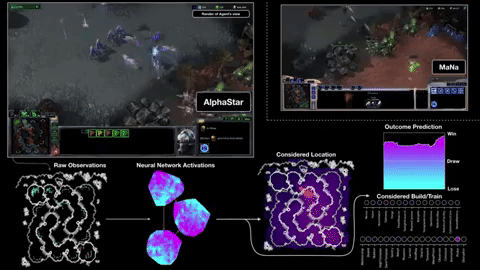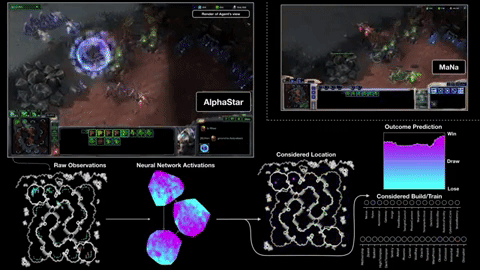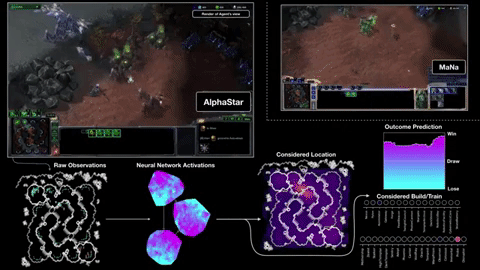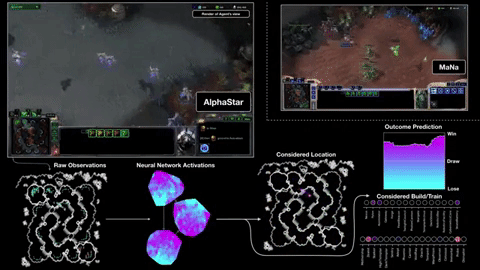 첫째, 게임 화면을 관찰하지 않고 게임 엔진에서 직접 정보를 얻습니다. 따라서 장치를 클릭하지 않고도 20 HP까지 내려갈 수 있습니다. 둘째로, 그것은 육체적 인 손과 버튼 뱅크에 의해 제한받지 않기 때문에 (항상 그렇지는 않지만) 사람보다 훨씬 더 많은 "분당 행동"을 수행 할 수 있습니다. APM은 성냥의 결과를 결정하는 많은 사람들 중에서 단지 하나의 척도이지만, 2 명 또는 3 명이 아니라 1 초에 20 명을 명령 할 수있는 상처를 줄 수는 없습니다.
첫째, 게임 화면을 관찰하지 않고 게임 엔진에서 직접 정보를 얻습니다. 따라서 장치를 클릭하지 않고도 20 HP까지 내려갈 수 있습니다. 둘째로, 그것은 육체적 인 손과 버튼 뱅크에 의해 제한받지 않기 때문에 (항상 그렇지는 않지만) 사람보다 훨씬 더 많은 "분당 행동"을 수행 할 수 있습니다. APM은 성냥의 결과를 결정하는 많은 사람들 중에서 단지 하나의 척도이지만, 2 명 또는 3 명이 아니라 1 초에 20 명을 명령 할 수있는 상처를 줄 수는 없습니다.
마이크로 컨트롤을위한 인공 지능이 오리지널 스타 크래프트에서 그 탁월성을 입증하면서 수년간 존재 해왔다는 사실은 여기서 주목할 가치가 있습니다. 치명적인 데미지를 입히거나 아무런 공격도하지 않아도되기 때문에 소방에서 유닛을 완벽하게 순환시킬 수 있다는 것은 믿을 수 없을만큼 유용합니다. 그러나 진실은 매번 좋은 전술을 능가하는 좋은 전략입니다. 좋은 선수는 AI의 완벽한 마이크로를 상쇄하고 가치있는 도구를 사용하지 못하게 할 수 있습니다.
AlphaStar는 경쟁이 치열한 Team Liquid의 두 명의 프로 선수, MaNa 및 TLO와 맞 섰습니다. 그것을 두 손으로 치고, 프로들은 기계 학습 시스템의 기술로 우울해하기보다는 흥분한 것처럼 보였다. MaNa와의 경기 2입니다.
게임 시리즈 후에 논평에서, MaNa는 말했다 :
AlphaStar가 내가 기대하지 않았던 매우 인간적인 스타일의 게임 플레이를 사용하여 거의 모든 게임에서 진보 된 움직임과 다른 전략을 끌어내는 것을보고 감명 받았습니다. 나는 게임 플레이가 실수를 강요하고 인간의 반응을 활용할 수 있는지 얼마나 많이 깨달았 는가에 따라 게임이 완전히 새로운 빛으로 변했습니다. 우리는 다가올 일을 보게되어 기쁩니다.
그리고 실제로 저그 (Zerg)의 주인공 인 TLO는 실험을 위해 프로토스 (Protoss)를 연주했습니다.
나는 그 대리인이 얼마나 강한가에 놀랐다. 알파 스타 (AlphaStar)는 잘 알려진 전략을 취해 머리를 돌립니다. 요원은 이전에 생각하지 못했던 전략을 보여주었습니다. 아직 완전히 탐구하지 못한 새로운 방식의 게임이있을 수 있습니다.
AlphaStar는 분명히 강력한 플레이어이지만 중요한 몇 가지주의 사항이 있습니다. 첫째, 그들이 인간처럼 놀아서 에이전트를 조작했을 때, 카메라를 움직여야하고, 보이는 유닛을 클릭 할 수 있고, 인간이 지각을 지연시키는 등등, 에이전트는 훨씬 덜 강력하고 실제로 MaNa에 의해 맞았다. 그러나 아마도 그 untethered 사촌보다는 벤치 마크가 될 수있는 그 버전은 아직 개발 중이기 때문에, 그 이유와 다른 이유로 결코 강하지는 않을 것입니다.
알파 스타 (AlphaStar)는 프로토스 (Protoss)만을 사용하며, 가장 성공적으로 사용 된 버전은 마이크로 무거운 유닛을 사용했습니다.
가장 중요한 것은, AlphaStar는 여전히 극단적 인 전문가입니다. 프로토스 대 프로토스 (Protoss versus Protoss) 만 플레이합니다. 저그가 어떻게 생겼는지 전혀 모르는 상태입니다. 게임을 한 사람이라면 누구나 말할 수 있듯이지도와 경주는 모든 종류의 변형을 만들어 내며 게임 플레이와 전략을 크게 복잡하게 만듭니다. 본질적으로, AlphaStar는 게임의 극히 일부분만을 재생하고 있습니다.
즉, 자체 교육 에이전트 설계의 기초는 어려운 부분입니다. 실제 교육은 시간과 컴퓨팅 능력의 문제입니다. Bloodbath에 1v1v1이라면 스토커 / 열정 시간 일 수도 있고, 2m2의 큰지도에 고도가 많으면 항공기가 나올 수도 있습니다. (내 SC2 스트럿에서 나는 분명하지 않니?)
프로젝트가 계속 진행되고 AlphaStar는 자연스럽게 강해지지만 DeepMind 팀 시스템의 기본 사항 중 일부는 (예를 들어, 모든 이동의 결과로 게임의 나머지 부분을 효율적으로 시각화하는 방법과 같이) AI가 반복적으로 결정을 내려야하는 많은 다른 영역에 적용될 수 있다고 생각합니다. 결과의 장기간 연속.