
만약 내가 당신의 방에 한 장의 사진을 보여줬다면, 아마 당신은 바로 눈앞 테이블이 있고 그 앞에 의자가 놓여 있고, 양자는 아마 거의 똑같은 크기로, 주황 이 정도 서로 떨어져 있고, 벽에서 이 정도 떨어져 있다고하는 것을 즉시 설명 할 것이다. 그 방 대충 한 평면도를 작성하는 데 충분하다. 컴퓨터 비전 시스템 은 이러한 공간 이해에 직감을 가지고 있지는 않지만, DeepMind을 이용한 최신의 연구 는 지금까지 이상으로 그 경지에 가까워지고있다.
이 Google 의 연구 기관에서 발표 된 새로운 논문은 오늘 (미국 시간 6 월 14 일) Science 지에 게재 된 (연구를 인용 한 기사 도 첨부되어있다). 이 논문이 상술 시스템은 사실상 아무것도 모르는 신경망이 1,2 장 정적 2 차원 영상을 보는 것만으로 거의 정확한 3D 모델을 구축한다는 것이다. 또한 여기에서 화제가하고있는 여러 스냅 샷에서 완벽한 3D 이미지를 구축 (Facebook이 그것에 종사하고있다)라는 이야기가 아니라 인간이 세계를 관찰하고 분석하기위한 직관적 에서 공간인지를 모방하려는 시도 다.
내가 "사실상 아무것도 몰라"라고 표현할 때, 그것은 단지 표준 기계 학습 시스템이라는 것을 의미하지는 않는다. 대부분의 컴퓨터 비전 알고리즘은 교사가있는 학습라는 것을 통해 작동한다. 교사가있는 학습은 인간이 정답을 붙인 대량의 데이터를 채 웁니다.
한편,이 새로운 시스템은 의지 할 수있는 그런 지식은 보유하고 있지 않다. 물체의 색이 끝을 향해 어떻게 변화 해 가는지, 거리가 변화함에 따라 얼마나 물체가 커지거나 작아 지거나하는 그렇다고, 우리가 가고있는듯한 세계를 보는 방법과 전체 독립적으로 동작한다.
대략적으로 말하면, 이것은 다음과 같이 동작한다. 시스템의 절반은 '표현'(representation) 부이며, 이것은 주어진 3D 장면을 어떤 각도에서 관찰하고 그것을 벡터라는 복잡한 수학적 형식으로 인코딩 할 수있다. 그리고 나머지 절반은 "생성"(generative) 부분이다. 이곳은 먼저 만들어진 벡터만을 기준으로 장면의 다른 부분이 어떻게 보이는지를 예측한다.
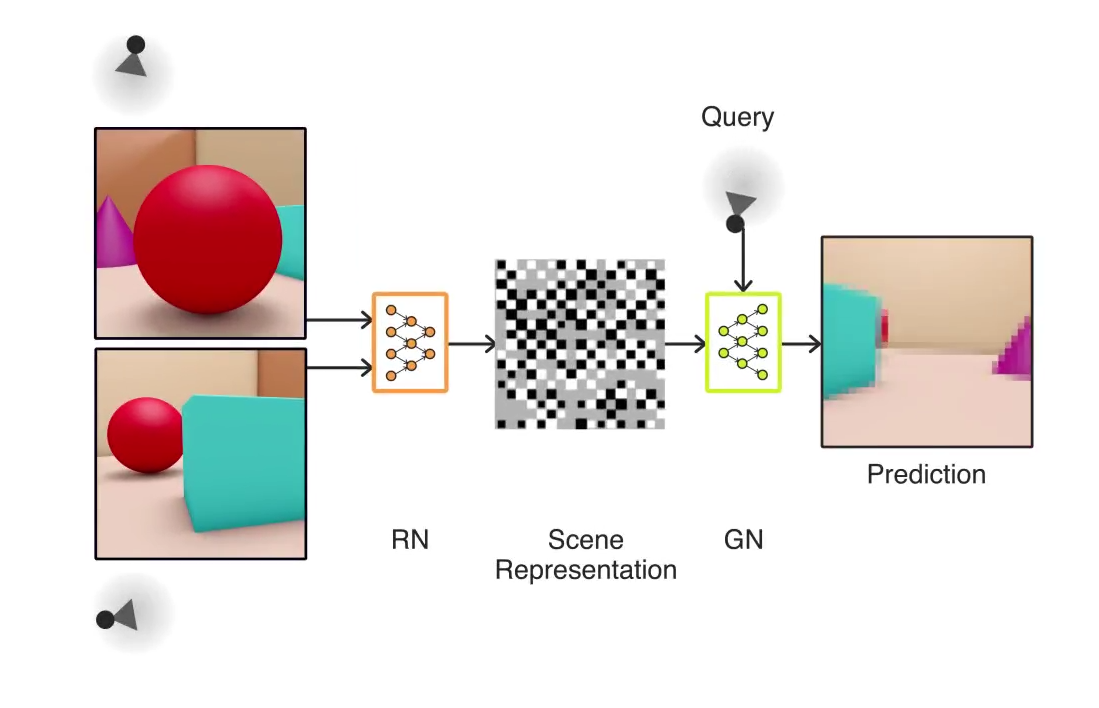
(이 방식을 좀 더 자세하게 보여주는 동영상은 이쪽 ).
예를 들어 당신에게 한 방 사진을 몇장 건네 오는 사람이 있다고 생각했으면 좋겠다. 그리고 그 사람은 당신에게 그 방에있는 특정 위치에 섰을 때 보이는 전망을 예상하고 그려달라고 부탁한다. 이 시스템이 할 것은 그런 기대 한 것이다. 반복하지만, 이것은 우리 인간에게는 목공도없는 것이다. 그러나 컴퓨터는 그런 일을 자연스럽게 할 수있는 능력은 가지고 있지 않다. 그들의 시각 (만약 우리가 그렇게 부를 수로 이야기지만)은 매우 초보적이고 상상력이 결여 된 것이다. 물론 기계 자신도 상상력이 부족하다.
그러나 숨어 보이지 않는 것이 무엇인지를 말하는 능력을 표현하기위한 적절한 말은 거의 존재하지 않았다.
"신경망이 이렇게 정확하고 제어 된 방식으로 이미지를 만드는 것을 배울 수 있는지 여부는 전혀 공개하지 않았다"고 논문과 함께 출시 된 기사에서 말한 논문 필두 저자 인 Ali Eslami이다. "그러나 우리는 충분히 깊은 네트워크는 인간 공학을 이용하지 않아도, 관점, 차폐, 조명에 대해 배울 수있는 것을 발견했습니다. 이것은 정말 놀라운 발견이었습니다."
또한 제시된 블록과 같은 단일 뷰에서 3D 오브젝트를 정확하게 재현하는 것도 가능하다.
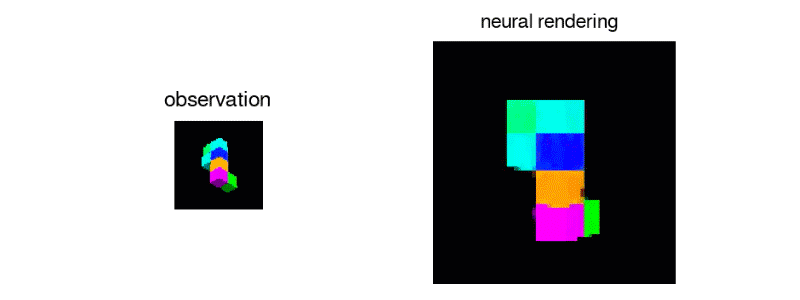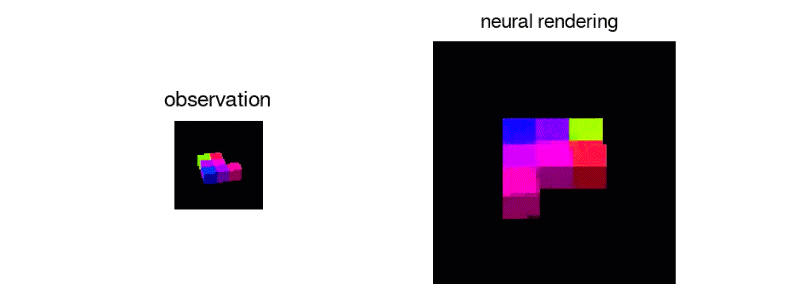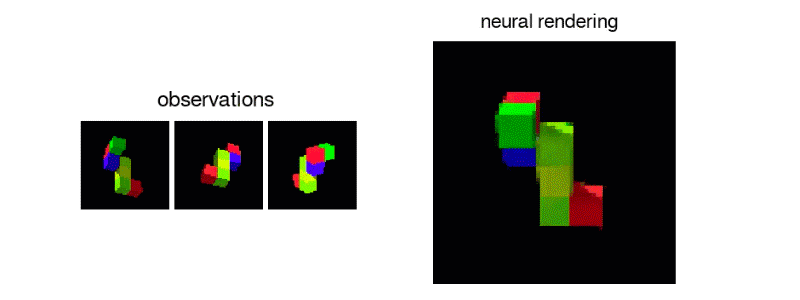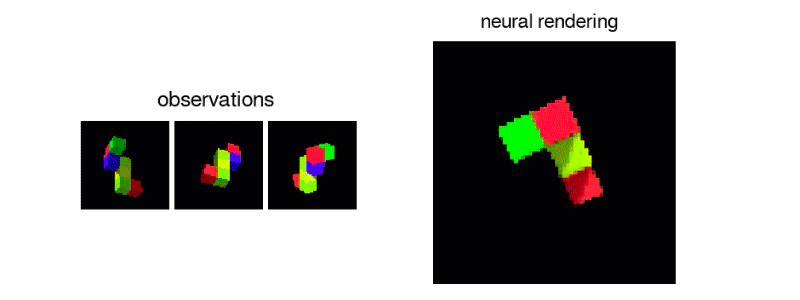
나 자신이 잘 할 수 있는지 자신이 없다.
분명히 하나의 관점에서가 블록의 일부가 카메라에서 숨겨진 방향으로 멀리 뻗어 있는지를 알 수 없다. 하지만 모든 방향에서보고 정확한 여부는 차치하고, 그런대로 그럴듯한 블록 구조를 만들어 낸다. 하나 또는 두 개 이상의 관측을 추가하여 시스템의 여러 뷰의 수정을 강요하지만, 그 결과 더 좋은 표현을 얻을 수있다.
이러한 능력은 로봇에게는 필수적인 것이다. 왜냐하면 그들은 현실 세계를 감지하고 본 것에 반응하여 현실 세계를 이동할 필요가 있기 때문이다. 중요한 단서가 일시적으로 시야에서 숨겨지는 등 제한된 정보에 의해 로봇이 멈추거나 비논리적 인 선택을 할 수있다. 하지만 로봇의 두뇌에서 이번과 같은 일을 할 것으로, 예를 들어 1 인치 간격의 정보없이 방 레이아웃에 대한 합리적인 가정을 할 수있게된다.
"이 새로운 유형의 시스템을 현실 세계에 소개하기 위해 더 많은 데이터와 빠른 하드웨어가 필요합니다"라고 Eslami는 말한다. "스스로 학습하는 에이전트를 구축하는 방법을 이해하는 방법으로 우리를 한 걸음 붙여주는 것입니다."