
Nvidia가 어제 (미국 시간 5/29) 발표 한 몬스터 HGX-2 는 괴짜의 꿈의 실현이다. 그것은 클라우드 서버 전용기라고 칭하면서도 고성능 컴퓨팅과 인공 지능의 요구 사항을 하나의 강력한 패키지로 만족시키고있다.
우선 모두가 신경이 쓰이는 사양에서. 프로세서는 16x NVIDIA Tesla V100 GPUs에서 처리 능력은 낮은 정밀도의 AI에서 2 페타 FLOPS 중간 정도라면 250 테라 FLOPS 최고의 정밀도는 125 테라 FLOPS이다. 표준 메모리는 1/2 테라 바이트에서 12 Nvidia NVSwitches 따라 300GB / sec의 GPU 간 통신을 지원한다. 이로 인해 종합 성능은 지난해 출시 된 HGX-1의 거의 배가된다.
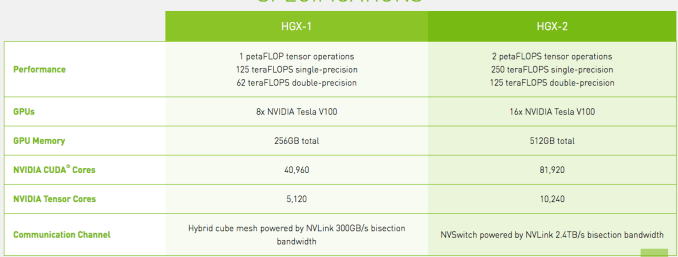
그림 제공 : Nvidia
Nvidia의 Tesla 데이터 센터 제품 담당 마케팅 매니저 Paresh Kharya에 따르면, 이만큼의 통신 속도가 있으면, 여러 개의 GPU를 하나의 거대한 GPU로 처리 할 수있다. "이를 통해 얻을 수있는 것은 엄청난 처리 능력뿐만 아니라 1 / 2 테라 바이트의 GPU 메모리를 단일 메모리 블록처럼 액세스 할 수있는 능력이다"라고 그는 설명한다.
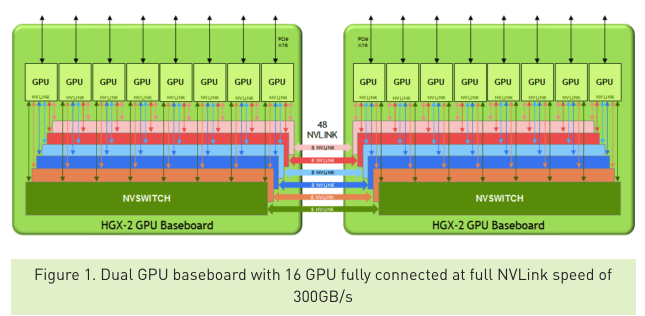
그림 제공 : Nvidia
불행히도이 상자를 최종 사용자가 직접 살 수 없다. 판매 대상은 오로지 하이퍼 스케일 데이터 센터 및 클라우드 환경을 최종 사용자에게 제공하는 인프라 공급자 소위 리셀러들이다. 따라서 리셀러는 원 박스에서 다양한 범위 (폭)의 정확도를 제공 / 제공 할 수있다.
Kharya은 이렇게 설명한다 : "플랫폼이 통일되기 때문에 기업과 클라우드 제공자 등이 인프라를 구축 할 때 단일 아키텍처만을 상대하면 좋고, 게다가 그 솔로잉이 고성능 워크로드의 전체 범위를 지원하는 .AI과 고성능 시뮬레이션 등에서 각 워크로드가 필요로하는 다양한 범위를 단일 플랫폼에서 제공 할 수있는 ".
그의 말에 따르면,이 것이 특히 중요한 대규모 데이터 센터이다. "하이퍼 스케일 기업과 클라우드 제공 업체는 규모의 경제를 안정적으로 제공 할 수있는 것이 매우 중요하다. 그러기 위해서라도 아키텍처가 산산조각이 아닌 것이 유리하며, 구조가 통일되어 있으면 작업의 효율성도 극대화 .HGX 절대로 그런 하나의 통일적인 플랫폼으로 표준화하는 것이 가능하다 "고 그는 말한다.
그리고 개발자는 그런 낮은 수준의 기술을 활용하는 프로그램을 작성할 수 있으며, 필요로하는 높은 정밀도를 하나의 상자에서 얻을 수있다.
HGX-2가 달리는 서버는 올해 Lenovo, QCT, Supermicro, Wiwynn 등의 리셀러 파트너에서 제공되는 것이다.